I wrote a bit about interactive fiction (IF) before on this blog – this time I want to talk a bit about how these games ticked and about an interpreter I wrote for them. If you haven’t read that, I recommend giving it a quick skim before reading this one, unless you’re already familiar with the genre.
Infocom
Back when interactive fiction first became a thing in the 70s, it was immediately a huge hit. Multiple companies sprung up to produce the stuff, including one called Infocom. I was remiss in my previous post in not mentioning them explicitly, but it’s time to set that wrong right. Infocom were responsible for games such as Zork, its many sequels, the official Hitchhiker’s Guide To The Galaxy text adventure, and many others. Like all companies, they held great interest in selling as much software as possible. In the 70s, 80s, and 90s, home computing wasn’t nearly as homogeneous as it is today. Now, we’ve basically settled on architectures based around the Windows, Linux (POSIX, if you want to be more accurate), and Macintosh operating systems. These in turn are built on top of hardware architectures such as the x86 or x64 instruction sets. But way back when, if you wanted to publish software on multiple different types of machine, this meant writing that software from scratch over and over again.
Virtual Machines
Naturally, companies were always looking for ways to cut down on development costs, and Infocom’s solution was to develop a so-called virtual machine. What I’m about to describe is not unique to interactive fiction – indeed, different types of virtual machine existed before the advent of IF. Many exist now – you only need to look as far as your favourite Java application to see an example of a virtual machine in action, as Java applications themselves run through software called a JVM (the appropriately named Java Virtual Machine).
A virtual machine is a program that takes as input compiled ‘bytecode’, and runs this code in the same way that a processor would run machine code. The genius of the virtual machine is that bytecode is portable. Provided a virtual machine exists for your target platform that is capable of running your bytecode, you can write the bytecode once and immediately be able to publish to that platform without thinking about the platform’s specific architecture. For instance, 24 games were written for version 3 of Infocom’s virtual machine, with virtual machine software developed for 15+ different platforms. So instead of having to write (24*15) 360 versions of their software, they needed to only produce the 15 virtual machines and the 24 games. So clearly the benefits of a virtual machine grow as you produce more software for it.
A virtual machine’s complexity could be measured in the number of ‘instructions’ it implements. For instance, one could imagine a basic virtual machine that takes as input compiled bytecode representing arithmetical expressions. The instruction set for a (very, very weak) machine might look like:
push number - push a number to the stack pop - pop the top number of the stack add - add all the numbers on the stack together, pop them, and push the result subtract - subtract the numbers on the stack from each other, pop them, and push the result multiply - multiply all the numbers on the stack together, pop them, and push the result divide - divide all the numbers on the stack using the oldest stack values as numerators first, pop them, and push the result print - print the result
Implementing such a virtual machine would be trivial – there’s no complicated input or output routines, nor graphical components. Indeed, the only output operation listed is for printing results. An example program would then look like:
# Add 3 to 4, then multiply by 2 and print the result push 3 # (stack: 3) push 4 # (stack: 3, 4) add # (stack: 7) push 2 # (stack: 7, 2) multiply # (stack: 14) print # prints 14
An actual program would be represented as some form of bytecode instead, rather than in text as above. Again, for example, a mapping between the instruction set and the bytecode:
push number -> 0x01 <number as byte> pop -> 0x02 add -> 0x03 subtract -> 0x04 multiply -> 0x05 divide -> 0x06 print -> 0x07
Which would make the above example code look like:
0x01 0x03 # push 3 0x01 0x04 # push 4 0x03 # add 0x01 0x02 # push 2 0x05 # mulitply 0x07 # print
Pretty simple, right? An interpreter would load a file like the above, examine a byte to determine what to do, and then perform that action before looking at the next instruction and starting again. We’ll talk about this loop later on. For another source on bytecode, you can checkout the Wikipedia article.
The Z-Machine
Infocom’s virtual machine is called the Z-Machine. They produced six different versions of it, each one adding significant complexity on top of the last. Five of them can be considered truly portable – you can take any game from those five generations and run them on any of the target architectures with a compatible virtual machine. The sixth version introduced graphics (!), and dropped the ‘write once, run anywhere’ philosophy for the game files themselves, with some changes necessary in the games themselves depending on the target architecture.
The instructions included in the Z-Machine are largely general purpose – there are very few specific to the genre of Interactive Fiction. All of the logic when it comes to interpreting player input and deciding what to print and when rests with the game code. For someone implementing a Z-Machine, their task is relatively simple – they need only implement around 60 instructions in order to support version 3 of the Z-Machine, and another 40 or so to support versions 4 and 5. Granted, some of these instructions are more complicated than others, and the implementer needs to understand the underlying architecture as well – things like how the object tables work, and how routines and instructions encoded. But as the implementer works through programming each instruction, they will end up having to develop the architecture as well.
Here’s a few (simplified) instructions implemented by the Z-Machine:
# @Var = Variable # @Dest = Destination address for storage or jump # #Num = Number literal # @@Vals = Vargs - some number of variables je @Var @@Vals @Dest # Compare @Var to all @@Vals and jump to @Dest if any @@Vals is equal to @Var store @DestVar @SourceVar # Store @SourceVar in variable @DestVar (@SourceVar can also be a #Num) get_prop @Var #Num @Dest # Get the #Num'th property of object @Var and store it in @Dest inc @Var # Read the value in @Var, increment it, and store it in @Var verify # Verify the game file by calculating a checksum and comparing it to a value in the file's header random @Var @Dest # Generate a random number between 0 and @Var and put the result in @Dest
As you can see, some instructions are simple enough to implement (store, je), while others (get_prop, verify) require a more in-depth understanding of the memory map and game file format.
For a more thorough history of the Z-Machine, please refer to this page compiled by Graham Nelson and others. In fact, that entire site is extremely useful as a reference for those implementing the Z-Machine, as it includes a full copy of the instruction table and an in-depth explanation of the architecture. The site proved invaluable when I was developing my own Z-Machine.
Fic
Fic is a V3 Z-Machine that I’ve written in Python, with the goal of eventually expanding up to V5. In a manner of speaking, this could make it a kind of meta-virtual machine, as Python itself is an interpreted language (distinct from a bytecode compiled language like Z-Code) which runs on any machine with a Python interpreter and appropriate libraries installed.
Rather than stand out as an engineering marvel, Fic exists to demonstrate how one may naively implement V3 Z-Machine in only a couple of thousand lines of code. Taking the time to properly architecture the code could cut this down dramatically – this is my next task now I have a working implementation.
So how do you go about writing one of these things? It turns out it’s surprisingly simple! Rather than go through the whole implementation, I’ll hit the key points:
- Loading a game file
- Determining where the program starts
- Decoding an instruction
- The program loop
Once this architecture is place, the ‘only’ work left is to implement all of the instructions!
Memory – Loading a game file
First, you need to load the game file into memory. As we’ll be dealing with bytecode, Python’s default open/read combo is sufficient:

The StoryLoader returns an instance of the Memory class. Memory is used to store the raw game data, as well as to provide easy access to the header elements. In the current incarnation of Fic, it’s also the ‘God’ class – it contains logic it shouldn’t should be refactored at some point.
The Header – Determining where the program starts among other things
Once you’ve loaded the game into memory, it’s time to do some basic housekeeping:

We keep a binary-string representation of the memory stored for special purposes like file verification, but more importantly we also keep a byte-array version of the data.
To start with, we can use this byte-array to read various header values and store them for convenience. This includes things like the version of Z-Machine being used (first byte, 0x00), the start locations of static and high memory (0x0e, 0x04), and where the dictionary table starts (a two-byte value called a word, stored at 0x08). At 0x06 (not pictured), the address of the first instruction resides. This last one is important, as it is our entry point into the program, and we will use it later to start the main loop.
Instructions & Decoding them
Instructions in the Z-Machine take the form of an ‘opcode’ (operation code), with zero or more arguments. In addition, if the opcode is used for branching, storage or printing text-literals, an additional parameter is provided to give the branch offset or storage location respectively. An instruction ranges from being a single byte long (0OP with no branch or storage, like verify) to unlimited (print opcodes with arbitrary length strings), although the longest non-print instruction can run up against 22 bytes. Opcodes are broken down into 4 categories in V3: 2-operand, 1-operand, 0-operand, and variable-operand. The opcode is determined by examining the contents of the first one or bytes, followed by determining the types of operands, the operands themselves, and the store/branch/text value (if any). This can get a bit complicated – see this little snippet from the getInstruction function that gets the operand types and operands themselves:

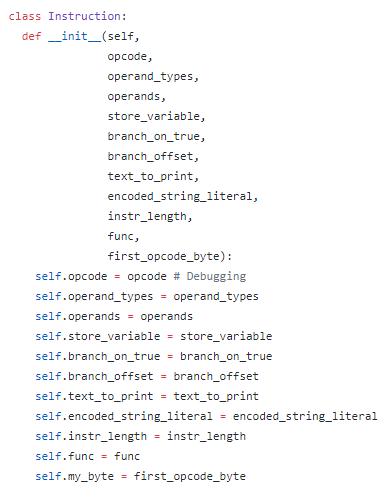
In addition to storing the obvious (opcode, operands, etc.), it’s also important to store meta-data about the instruction, whether for practical or debugging purposes. For instance, it is important to know the length of an instruction in order to correctly place the program counter after running the instruction. Here’s what the Instruction class looks like. A call to getInstruction will return one of these when provided an address.
The Main Loop and Program Counter
Now for the easy bit. We know the address where the program begins thanks to the file’s header. We also have a function for determining the instruction to run when given an address. So we set the program counter of the interpreter to this address, and kick off the main loop:

If you ignore the debug statements, the loop body is two lines long! How does this work? Well, first we fetch the instruction pointed to by the ‘pc’ variable, which refers to the program counter. We then run that instruction. Each instruction will affect the program counter in one of two ways:
- It will increment the program counter by its own length, thereby pointing to the next instruction for the next loop iteration, or…
- It will manipulate the program counter directly, either setting it to a specific value (in cases of function calls or return statements), or adding/subtracting some offset value (in cases of jump instructions).
In other words – the end result of the loop is that the program counter is pointing at a new instruction, so the loop can begin again from the top. This will continue until the program triggers an opcode to end the game (or the user sends an interrupt to kill Python).
Now what?
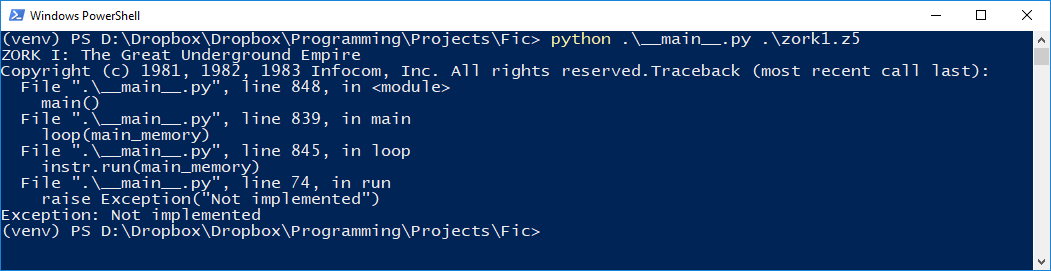
If you review my first commit on Fic, the above is all I implemented to start with. With this in place, I took the naive approach. I used Fic to run Zork 1. Of course, it failed – I didn’t implement any opcodes! Any attempt to run an opcode that was not yet implemented triggered an exception (“Not implemented”), meaning I had more work to do. Implementing an instruction is easy enough if the architecture is in place – I just have to define a function inside the Memory class that takes an instruction as a parameter that manipulates the memory accordingly. For example:
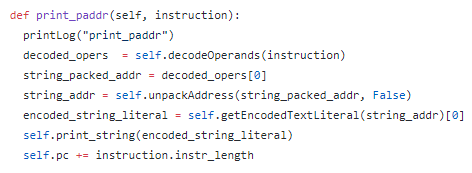
This is what the print_paddr instruction implementation looks like. All of the heavy lifting logic is abstracted out, but the idea is clear. First, get the decoded operands from the instruction. Then, the first operand is the location of the string literal we want to print. However, it is offset by some amount, so we first unpack the address. Then, we can fetch the string literal at that address, and finally (!) we can print it to the screen. As is normal, we then set the program counter to be after this instruction.
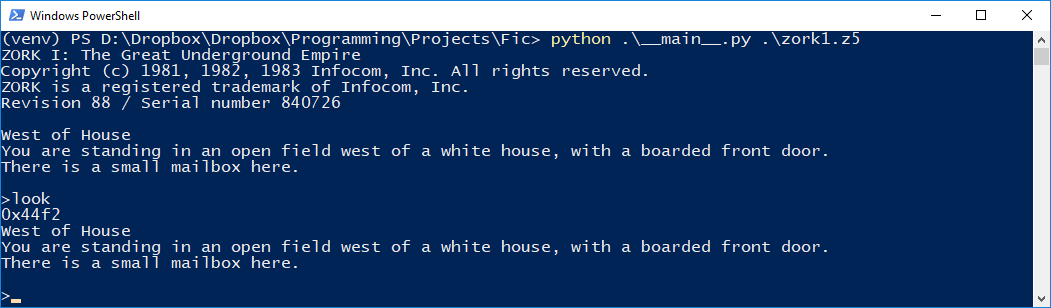
So I implemented these opcodes, over and over, learning more about the Z-Machine architecture with each one. For instance, the first few opcodes used in Zork 1 are ‘call‘, ‘add‘, and ‘je‘ – immediately, with call, a would-be implementer is thrown in at the deep end, and must learn how to implement routines and the call stack. With je, the implementer must understand Z-Machine branching behaviour. After some persevering, the code reached a stage where it would print one of the opening lines of the game!
And after a few more commits, we had the command prompt (with some debug strings hanging around)…
And after a year of on-and-off work (okay, fine, maybe ten days of actual effort if you look at the commit history):
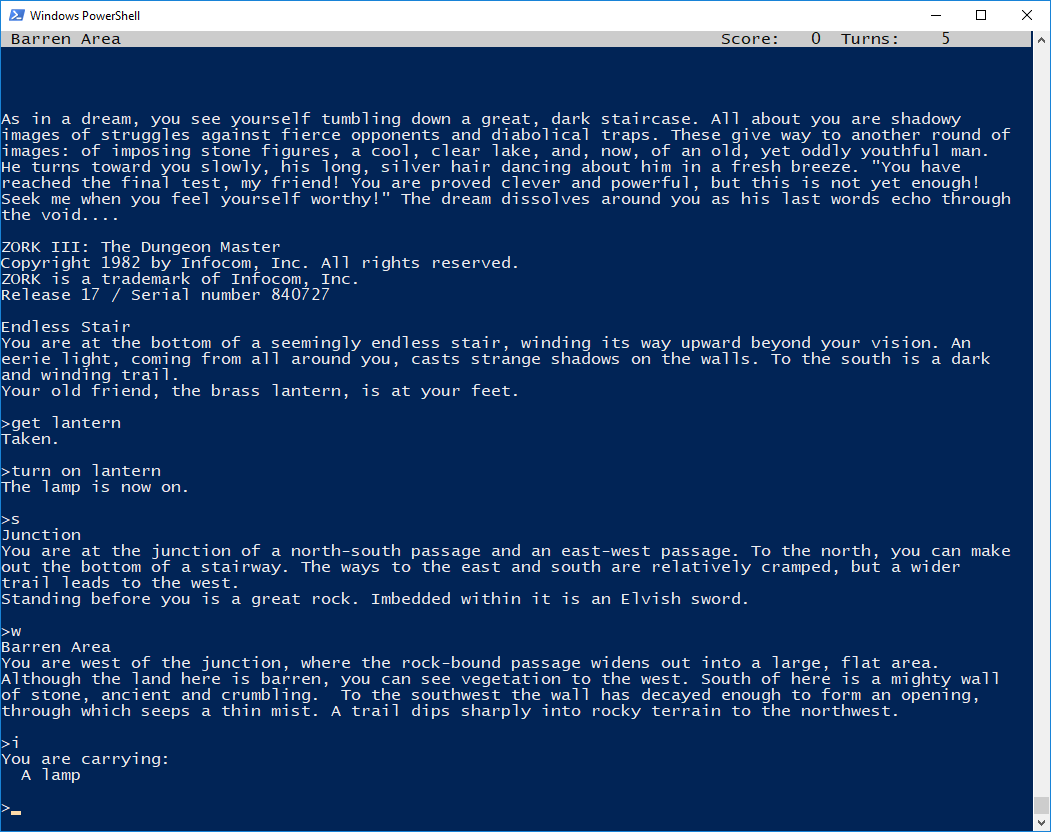
This is Fic running Zork 3. Note the fancy status bar at the top of the screen, the lack of random debug strings or text bugs..! If I’ve done my job right, it should be possible to reach the end of the game as the developer intended with none of those nasty ‘Not implemented’ errors or random crashes.
That’s it!
I encourage you to take a look at the source for Fic if you’re interested in how a novice in virtual machines might go about implementing a simple one. A few warnings before you go looking:
- It’s untidy and need of refactoring – the sole source file is 2k SLOC.
- It’s incomplete – some non-mandatory V3 instructions are missing.
- There are omissions and likely errors in how the specification is meant to be followed, so if you’re using it as an example of how the Z-Machine should be implemented… don’t! Instead, look at WinFrotz or something similar.
Thanks for reading – I hope you found it interesting!